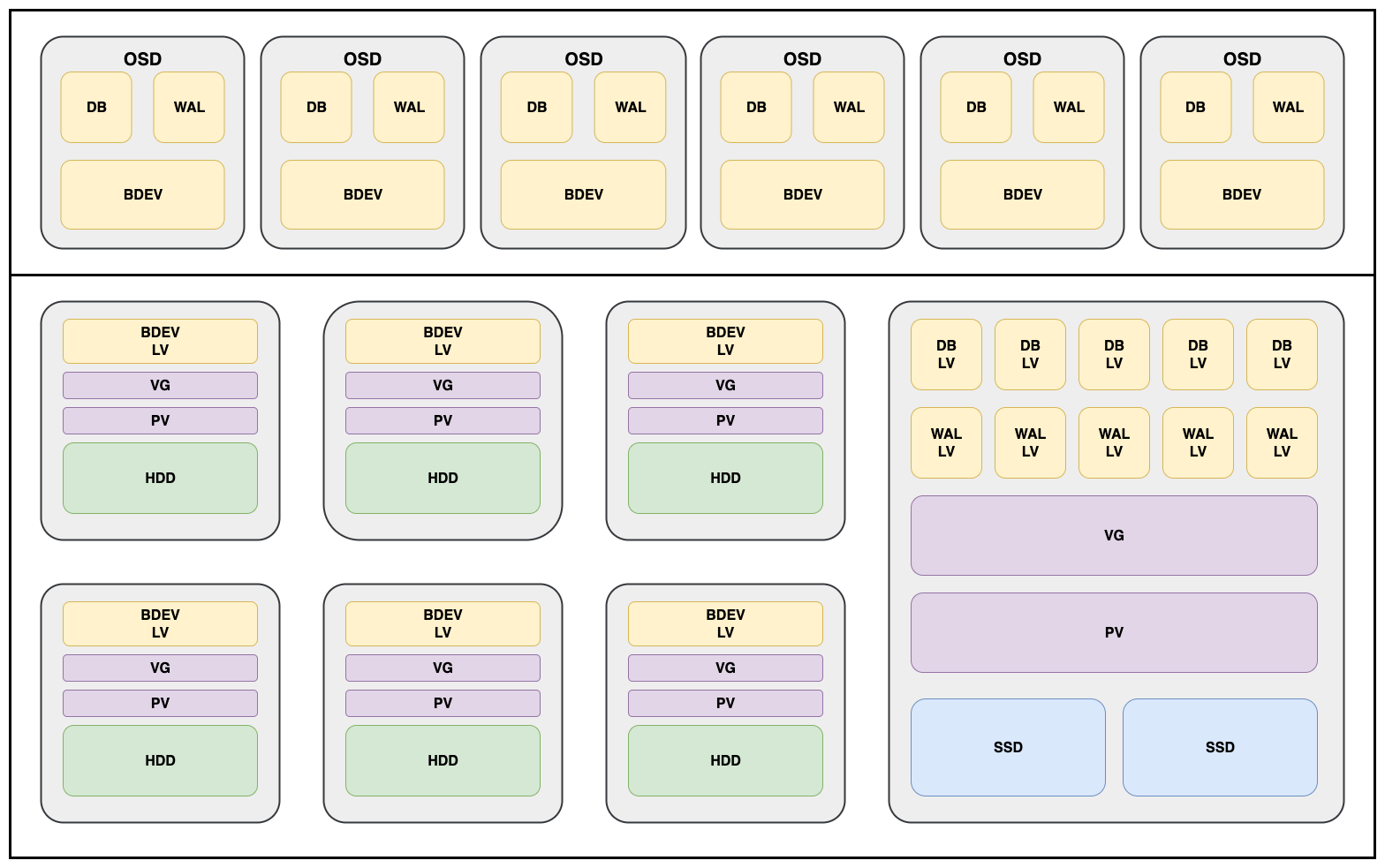
TLDR:将CEPH OSD的DB/WAL从block设备中剥离单独部署到SSD设备中
家里的CEPH集群除了一块NVME用作虚拟机的块存储之外,其他都是使用纯机械盘部署的slow volume osd。正好手头有4块闲置的480G SATA SSD,想着用来加速这些HDD OSD。
加速方案
最终选择了bluestore原生的DB/WAL设备独立部署的方式,没有选择用bcache或者flashcache方案加速bdev设备一是因为SSD空间有限,再则CEPH官方也不再推荐嵌套缓存加速技术。
CEPH OSD从bluestore开始,由bdev块设备、wal和db组成。
WAL是元数据预写请求日志,后续定期落到RocksDB中,建议10-20GB per osd。
DB是元数据数据库,建议OSD Block设备容量的4%,丢失即OSD数据损毁。正因如此,每个节点使用一组raid1的SSD,为节点所在osd提供wal/db分区。
LV容量规划
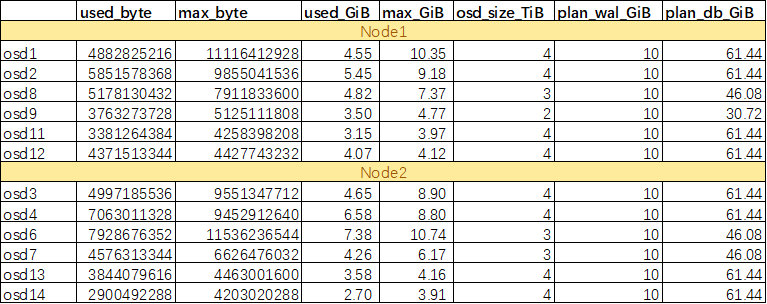
由于SSD空间紧张,WAL分区每个OSD给了10G,DB按照1.5% HDD容量分配。但是要注意DB分区空间不能小于当前OSD RocksDB所用空间大小。
使用ceph daemon osd.{osdid} perf dump确认db_used_bytes和max_bytes_db。这里分配1.5%还是比较保守的,并且由于使用LVM分区作为DB/WAL设备,后期也可以很方便地进行扩容。
迁移方案
LLM给出的方案中,有说需要清空PG重新创建OSD的,有说用ceph-bluestore-tool工具迁移的,或者重新定义orch资源文件,说是无需重建PG,没验证过不敢确保可行。最后用的是ceph-volume lvm new-wal 和ceph-volume lvm new-db直接附加新的LVM分区作为DB/WAL给OSD。
说明一下现场环境,ceph集群使用cephadm部署,runtime是docker,ceph版本是19.2.2,osd进程使用orchestrator部署管理,验证可行。
迁移过程
制备DB/WAL所用的LV
这里软raid直接使用lvm原生的raid而不是mdadm,好处是以后扩容时无需先扩容阵列,性能层面软raid估计大差不差。
# 创建PV
pvcreate /dev/sdf /dev/sdg
# 创建VG
vgcreate ceph-db-wal /dev/sdf /dev/sdg
# 创建RAID1 LV 注意osd id
lvcreate --type raid1 -m 1 -L 10G -n osd-1-wal ceph-db-wal
lvcreate --type raid1 -m 1 -L 61.44G -n osd-1-db ceph-db-wal
附加DB/WAL设备并且迁移DB
注意需要在osd所在节点使用cephadm shell进入对应osd操作。
操作前首先在集群范围增加noout、nobackfill、norebalance标签,防止数据迁移。操作过程需要停止osd进程。
ceph orch daemon stop osd.1
./cephadm shell --name osd.1
OSD_FSID=$(ceph-volume lvm list 1 | awk '/osd fsid/ {print $3}')
echo $OSD_FSID
# 附加独立的db设备,这时会看到/var/lib/ceph/osd/ceph-1/下产生了block.db
ceph-volume lvm new-db --osd-id 1 --osd-fsid $OSD_FSID --target ceph-db-wal/osd-1-db
# 迁移db数据,参考https://docs.ceph.com/en/reef/ceph-volume/lvm/migrate/
# 这里的--from data指从osd迁移db到新的lv,而不是使用--from db。参数设计得有些反直觉,总会让人理解成会把bdev设备迁移到新的lv。
ceph-volume lvm migrate --osd-id 1 --osd-fsid $OSD_FSID --from data --target ceph-db-wal/osd-1-db
# 附加独立的wal设备,wal设备无需迁移数据。
ceph-volume lvm new-wal --osd-id 1 --osd-fsid $OSD_FSID --target ceph-db-wal/osd-1-wal
ceph orch daemon start osd.1
osd启动后检查元数据,检查bluefs_db_devices和bluefs_wal_devices是否是新附加的设备。
ceph osd metadata 0 -f json
如果需要把db迁回到main设备的话
ceph osd add-noout osd.1
ceph orch daemon stop osd.1
cephadm shell --name osd.1
ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-1/ --command bluefs-bdev-migrate --devs-source /var/lib/ceph/osd/ceph-1/block.db --dev-target /var/lib/ceph/osd/ceph-1/block
# 需要首先移除db的lv,不然启动osd时会自动使用独立的db设备
lvremove /dev/ceph-db-wal/osd-1-db
ceph orch daemon start osd.1
ceph osd rm-noout osd.1
后记
至此已经将OSD的DB和WAL设备单独部署到了SSD设备上,不过要注意这么做只是加速了OSD的元数据操作,因此看起来大文件的持续读写带宽并没有太大的提升。操作本身并不复杂,但是切记做好备份,虽然ceph集群本身能够提供一部分数据健壮性,只要同时只操作一个OSD就问题不大。这次没有经过测试环境验证就敢直接上的底气还是来自于磁带的全量备份。