
最近把爸妈家那台冷备nas里的硬盘收拾了下,插到了ceph集群里。另外又做了个硬盘柜,两个节点各连一个,节点HBA卡还有一个SFF8087可以各自再加一个柜,还要加的话就要用SAS Expander去扩展物理接口了。ceph的扩展性是毋庸置疑的,这次加的盘有2T有3T的,只要各OSD节点尽可能容量平衡,硬盘大小品牌都无所谓。如果不在乎故障域隔离的话,修改crashmap无视节点容量平衡也无所谓。
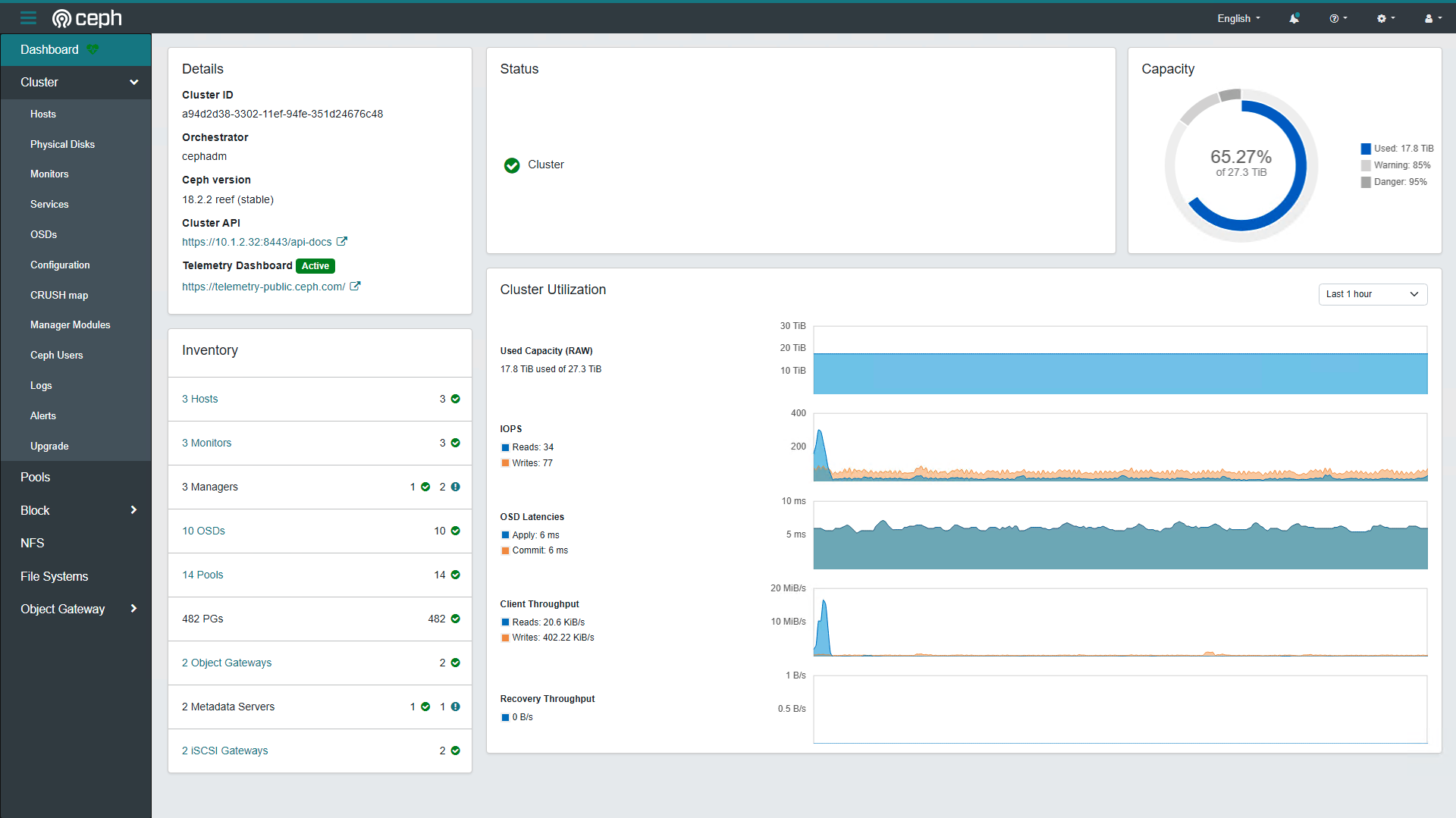
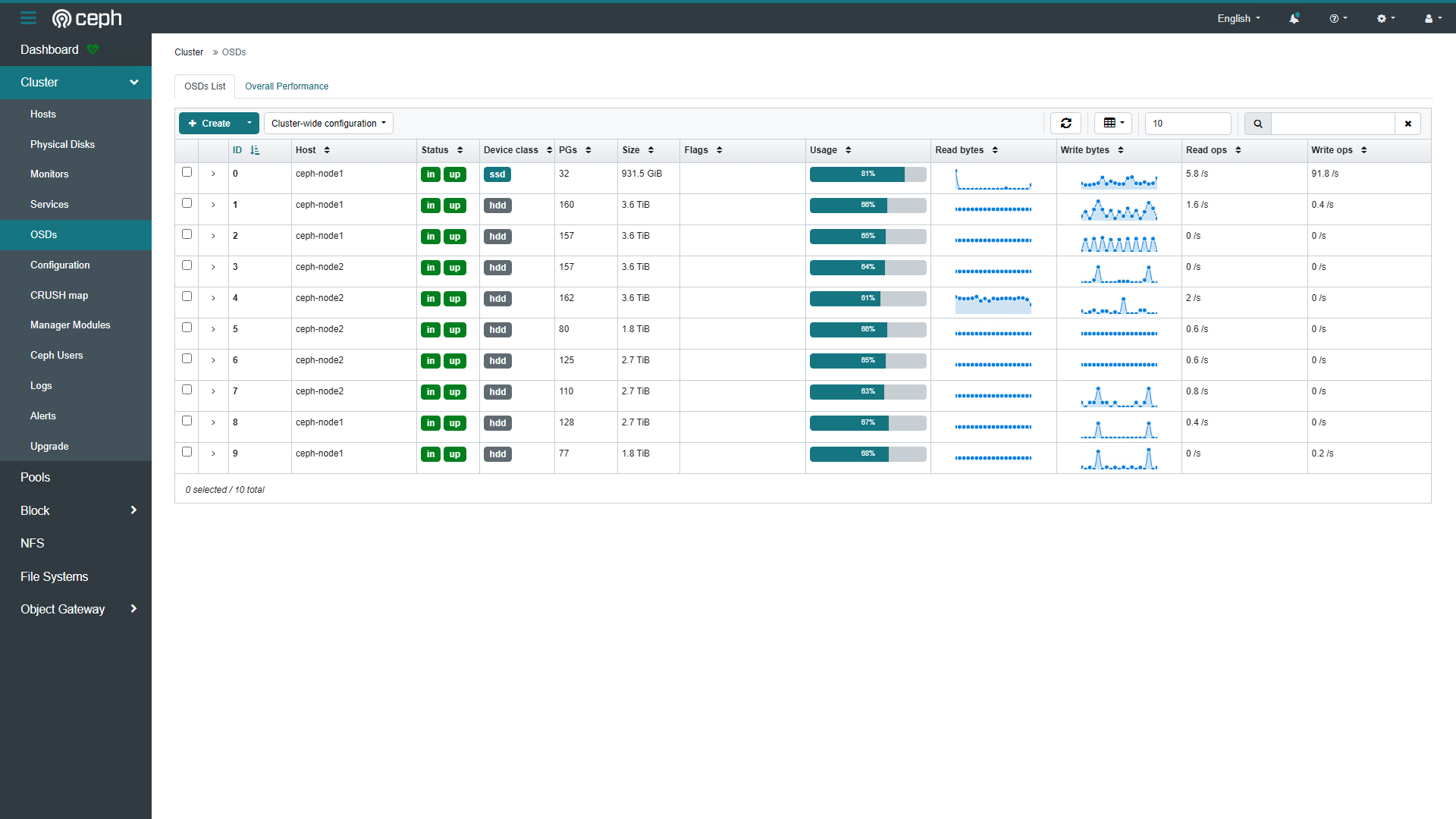 用量现状
用量现状
带宽
关于集群网络,只能说能用10G就不要用千兆,不管是副本池还是纠删池,分布式存储就意味着读写的时候需要跨节点去取数据,所以如果是单千兆的网卡在业务平面是跑不满千兆带宽的。
这里就体现出了桌面PC的劣势,PCIE通道不够用,桌面系列CPU一般都只有24条pci通道,4条给南桥,剩下一般都是一个x16和一个x4给m.2。而ceph osd节点,HBA、10G NIC、若干条NVME SSD,每一个都需要x4的通道,而桌面级主板一般都是给显卡的x16接口,这就对通道的拆分能力有要求,并且用了拆分卡后机箱的PCI挡板固定位就无法用原位,甚是尴尬。更尴尬的是,我的M520准系统主板的BIOS不支持pci拆分,用不起高贵的带PCI SWITCH的拆分卡,现在只能放弃10G NIC,HBA用X16,NVME用南桥出来的两个可怜的x1。
所以,还得是Server平台才行。要不是功耗和噪音…哎,总有一日搞个光伏系统,就没有用电顾虑了。
一些小知识
pg scrub
就像老唱片一样,系统会定期检查各个PG,拿出来掸一掸灰看看有没有破损然后放回去,默认是1-7天一次scrub,7天一次deep-scrub,可以修改osd_deep_scrub_interval、osd_scrub_min_interval、osd_scrub_max_interval调整。
如果某个PG超过了阈值没有scrub,会提示PGs have not been deep scrubbed recently,可以手动触发scrub。
ceph health detail
ceph pg deep-scrub [pgid]
pg repiar
某些时候会提示PG不一致需要修复。
rados list-inconsistent-pg [poolname]
ceph pg repair [pgid]
也可以修改osd_scrub_auto_repair开启自动修复。
pool crush rule
关于存储池的策略,我目前rbd用的是2副本的副本池,cephfs用的是ec3+1,加了硬盘之后本来想改成6+2,这样可以容许多坏一块硬盘,但是发现无法直接修改ec规则。
如果是副本池的话,可以随时调整副本规则,存储池会自动调整数据。如果是纠删池的话,Erasure code profile是无法修改的,也无法直接修改k、m值,看起来只有重新创建一个pool导一遍数据。
使用ceph的客户端
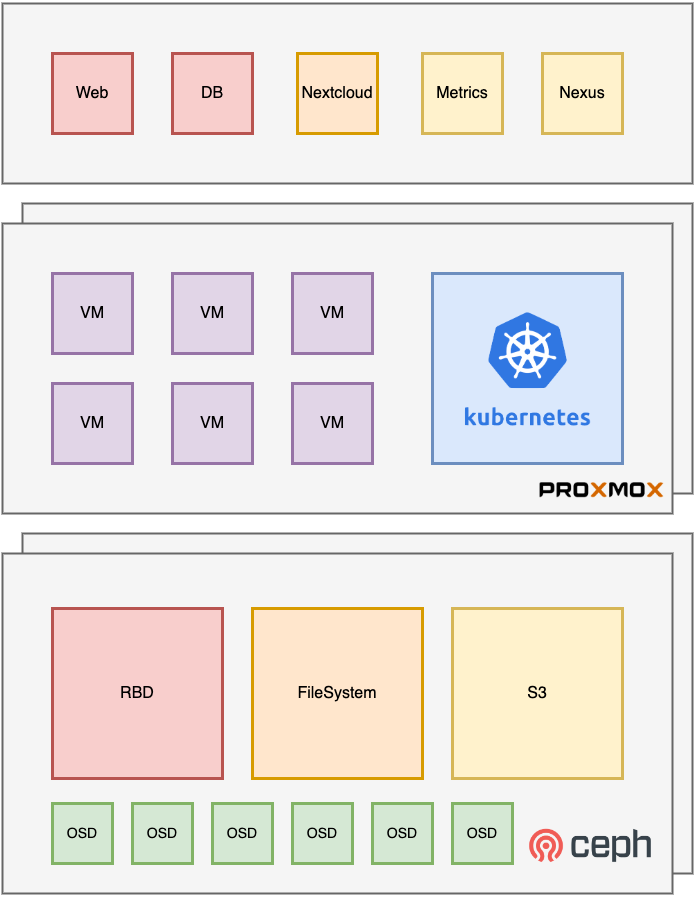
linux就正常用内核驱动,windows可以用iscsi连rbd也可以用dokan的库链接rbd或者cephfs。PVE引导的时候可以用iscsi。
pve使用cephfs的时候有一个不容易注意的参数,subdir,如果共用cephfs的filesystem并且不想目录结构看上去乱七八糟的话。因为pve会自动创建template目录。需要在storage.cfg中编辑,web后台引导创建的时候没有。
k8s的话ceph官方提供了ceph-csi。甚至可以用rook-ceph的external-cluster模式由rook-ceph代理一个。
关于smb,18.2.2的cephadm中至少还没有原生的smb service,但是在latest的Doc中能够看到有samba服务。至于现在,可以用linux挂载cephfs后提供smb服务。